Introduction
You can find the entire code for this project (the newer version) on my Github
For most of my programming career, I have stayed in the realm of writing CLI programs. Ever since I was a student, back in college, I remember most, if not all of our assignments were stuff controlled by the terminal. You know, just typing commands on the console, yeah, a CLI. Lots and lots of CLIs.
Many programmers and developers tend to move on, in a quite fast manner, onto other stuff, most commonly web development. Actually, most software engineers, and even non-technical people usually automatically relate software engineering to web development. Recruiters and managers and other people usually think webdev, programmer and software engineer are all synonyms. Most software engineering roles or openings for jobs you see online are straight up webdev roles, be it frontend, backend, or full-stack. And let’s be honest, for many, possibly the majority of programmers, webdev is all they care for.
I always disliked this idea and tried to keep my distance with the concept. For years and years I’ve tried to avoid web development. I didn’t knew what I wanted to do, or what kind of programmer I wanted to be. I just had a vague idea of what I wanted to do, mixed with the strong idea that I just refused to do anything webdev related. Through my mind, I had thoughts of “maybe writing desktop software, or something, I don’t know” whenever someone asked me what kind of programming I wanted to do. It was just a thought in the air, it didn’t really exist as a solid idea. I just knew I wanted to avoid webdev at all costs.
Until somewhat recently, around 2023, when I just gave up and realized I couldn’t escape the webdev, especially if I wanted a job. So I started to learn some backend stuff, which I kind of enjoyed.
Still, a certain “itch” sticked with me. I kept having a weird systems programming or low-end interest or hunger. I decided to learn Rust, for whatever (mostly impulsive) reason, I read the book, half understanding it, then moved onto C++, then back to Rust and then back to C++ in a very silly and weird language hopping game that lasted for quite some months, and maybe still.
Of course, life happened.
Trying to get a Software Engineer job in 2025 is no joke. I start to believe it is straight up impossible. I tried doing some backend-ish projects for my portfolio to try and land a job. No luck so far. But I’ll try to keep this part of the story short.
The thing is, I’ve been focusing on other areas of my life, like my current (non software related) job. Also trying to exercise, reading a lot, and that kind of stuff. And very recently I started diving into recreational programming.
The spark
After reading a good chunk of The Rust Programming Language (the official Rust book), I was feeling lost, without knowing what to work on. I’ve always been pretty damn bad at choosing projects. So I kept on writing toy, CLI projects. But at some point I came accross PNGme (GitHub), an intermediate project to reinforce Rust language skills. At first it was quite hard and I had no idea how to move on, but I slowly pushed through it. The entire project took me around a week to complete. This project consists of metadata-based message embedding in PNG files. It allows the user to embed and retrieve hidden messages using standard PNG Chunk structures. It modifies that metadata structure, rather than modifying pixel data. It was quite interesting to see it working. You pass the program a PNG file, a text message, and the program just seemingly leaves the image untouched, although, if you pass the same image to the program but ask it to decode, or retrieve the hidden message, it prints it in the screen. It uses raw byte manipulation to alter the PNG chunks, ensuring the integrity of the image remains intact. Cool stuff.
Interestingly, or ironically, despite fully completing this project, and even besting the number of problems or struggles I had through it, I unfortunately was not fully aware of some of the knowledge required to implement it. Like I said before, I pushed through the project, slowly but surely, and using an LLM to help me better understand some concepts or some code (not asking it for the solution or implementation of blocks of code). But still, something was not fully “clicking”. So I just kept reading around, practicing writing some programs, nothing too specific, and that kind of stuff, while balancing the rest of my life.
Unfortunately I’ve done a lot of language hopping. I’ve been moving around from Rust, to C++, to Go, back to Rust, then repeat the cycle. And lately C! Although it feels like a big waste of time, and I keep being told that I should focus on one and only one language for being productive and better learning, I’ve changed my mind about it quite a bit. Now, in retrospective, I am kind of grateful I’ve been doing so much language hopping. I think I understand way more modern programming concepts or paradigms and, despite the usual mental resistance during the first few hours or days of writing on a language I haven’t used in a while, it feels as I am in a way better position to use any language. Like, learning about Option<T> and Result<T, E> on Rust helped me grasp better a method to elegantly manage errors, and now I notice more easily how managing errors work in other languages. Understanding more or less how std::vector<T> works in C++ helped me better understand how certain tools are implemented in different languages, and so on, just to mention some examples…
Anyway, despite doing all this language hopping, I was still mostly project-less and without knowing for sure what the hell to do as a good project. And this kept on for weeks. Until recently, when I decided to check out once again CS50: Harvard’s Introduction to Computer Science. That course is great because it starts you up with C, althought with training wheels, but still, lots and lots of C. So, at one point, one of the Problem Sets requests the student to open up a file and directly read its contents, as in, raw bytes. You then need to correctly interpret those pointers and, using structs and other methods, modify them correctly. For example, we were dealing with BMP files (bitmap), and we are asked to apply certain instagram-like filters to those images, like sepia, blur, and that kind of stuff. I’ve completed this Problem Set in the past, as I’ve finished CS50 before, but this time, I was solving the problem sets one by one up to this point, in order to refreshen my C. When I got to this point, I came up with my own idea for a project.
The idea
So, if I was already getting familiar with opening files and interpreting its byte structure, first by reading WAV files and then with BMP files, what was stopping me from at least trying to open and interpret other file formats?
That’s when I learned that, in layman’s terms, every file is just a series of bytes organized in a specific structure. Every file has ingrained within itself a way to let the program or programmer know what type of file it is and how to use it. So I decided to continue along the same idea about the BMP files, but this time with PNG files. After all, I already had some experience working with PNGs, right?
So I began working and, surprisingly, the code started flowing. I won’t lie, again, I used an LLM to assist me. But not Cursor or anything similar. I only asked ChatGPT for guidance. Never asked for solution code to anything. This makes for a great way to learn.
The code (in pure C)
Opening the file
We begin by opening the file, of course:
int main(int argc, char *argv[]) {
if (argc != 2) {
printf("Usage: ./reading <png file>\n");
return 1;
}
// Open input file
char *infile = argv[1];
FILE *inptr = fopen(infile, "rb+");
if (inptr == NULL) {
printf("Could not open %s\n", infile);
return 1;
}
}
This is pretty straightforward stuff, checking for the correct amount of command-line arguments and thus, correct usage, then opening the file.
Checking if we have a valid PNG file
Taken from PNG Specification.
It starts getting interesting when we try to make sure this is a valid PNG file. The first eight bytes of a PNG datastream always contain the following values:
In hexadecimal:
89 50 4E 47 0D 0A 1A 0A
Or in decimal:
137 80 78 71 13 10 26 10
This is called a Signature Header. It indicates that the remainder of the datastream contains a single PNG image, consisting of a series of chunks beginning with an IHDR chunk and ending with an IEND chunk.
So the code to obtain these bytes and check for an existing (and correct) Signature Header looks like the following:
// PNG Signature. It is always the following values
const uint8_t png_signature[] = {137, 80, 78, 71, 13, 10, 26, 10};
// Struct for the Signature Header
typedef struct {
uint8_t values[8];
} __attribute__((__packed__)) PNGSIGNATUREHEADER;
// Checks for a valid Signature Header
bool valid_SH(PNGSIGNATUREHEADER *signature_header, FILE *file) {
if (fread(signature_header, sizeof(PNGSIGNATUREHEADER), 1, file) != 1) {
printf("Error: Couldn't read Signature Header.\n");
return false;
}
// Compare each element in the Signature Header
for (size_t i = 0, n = sizeof(signature_header->values) / sizeof(uint8_t);
i < n; i++) {
/* printf("%02x ", signature_header->values[i]); */
printf("%u ", signature_header->values[i]);
if (signature_header->values[i] != png_signature[i]) {
printf("Mismatch in Signature Header.\n");
return false;
}
}
return true;
}
And we call it in main like:
int main(int argc, char *argv[]) {
[...snip...]
// Read infile's PNGSIGNATUREHEADER and determine if
// it is a valid PNG file
PNGSIGNATUREHEADER sh;
if (!valid_SH(&sh, inptr)) {
printf("Not a valid PNG File.\n");
return 1;
} else {
printf("Valid PNG file.\n");
}
[...snip...]
}
At this point, if the user used as input a valid PNG file, the program will recognize and check its Signature Header and will reply with the case.
Reading the Chunks
This is where it starts getting not only interesting, but complicated. We now have to start reading chunks one by one until we run out of them. The layout of a chunk of a valid PNG consists of three or four fields. And they look like the following:
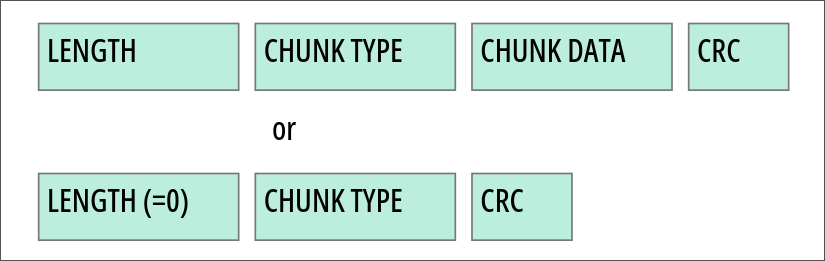
And we can think of them like follows:
- Lenght A PNG four-byte unsigned integer giving the number of bytes in the chunk’s data field. The length counts only the data field, not itself, the chunk type, or the CRC. Zero is a valid length. Although encoders and decoders should treat the length as unsigned, its value shall not exceed 2^(31)-1 bytes.
- Chunk Type A sequence of four bytes defining the chunk type. Each byte of a chunk type is restricted to the hexadecimal values 41 to 5A and 61 to 7A. These correspond to the uppercase and lowercase ISO 646 [ISO646] letters (A-Z and a-z) respectively for convenience in description and examination of PNG datastreams. Encoders and decoders shall treat the chunk types as fixed binary values, not character strings. For example, it would not be correct to represent the chunk type IDAT by the equivalents of those letters in the UCS 2 character set.
- Chunk Data The data bytes appropriate to the chunk type, if any. This field can be of zero length.
- CRC A four-byte CRC calculated on the preceding bytes in the chunk, including the chunk type field and chunk data fields, but not including the length field. The CRC can be used to check for corruption of the data. The CRC is always present, even for chunks containing no data.
We could dig deeper into the Chunk Naming conventions but that’s a little out of scope for the current exercise.
The IHDR Chunk
A valid PNG file’s first chunk is always IHDR, which stores information about the image itself. So in the following code, I first and foremost tried to obtain all the chunks in a proper struct for structured and clean usage. It looks something more or less like the following:
#include "chunk_type.h"
// defines the Chunk Type
typedef struct {
char type_code[4];
} __attribute__((__packed__)) CHUNK_TYPE;
// defines a Chunk
typedef struct {
uint32_t length;
CHUNK_TYPE chunk_type;
uint8_t *data;
uint32_t crc;
} __attribute__((__packed__)) CHUNK;
// Reads a chunk from file
CHUNK *read_chunk(FILE *file);
The full code for the ‘read_chunk’ function is kind of long and verbose. I would love to show it here in its full (noobish) glory but for the sake of not making this article very huge, I’ll keep only the function signature, for now, with a few snippets down below. All you need to keep in mind for now is that the function receives a pointer to a FILE, makes the proper checkings to see if it is a valid, open file, and then does certain memory allocations to validly store the struct fields. For example, we need to allocate enough memory for a chunk of type Chunk, and then, first of all, obtain and store the length field, then pretty much the same thing for the Chunk Type, which involves another struct of its own, and then the actual data and the CRC. It looks something more or less like the following, although I’m only showing here the chunk and length.
Actually reading a full Chunk
// Allocating memory for chunk
CHUNK *chunk = malloc(sizeof(CHUNK));
if (chunk == NULL) {
printf("Error allocating memory for Chunk.\n");
return NULL;
}
// Read length
if (fread(&chunk->length, sizeof(uint32_t), 1, fileptr) != 1) {
printf("Error: Couldn't read bytes for Length.\n");
free(chunk);
return NULL;
}
chunk->length = swap_endian(chunk->length);
Calling the read_chunks function and checking for the IEND Chunk
So we pretty much use this function inside a loop, reading chunks over and over. When do we stop? When we find the IEND chunk. Just like a Signature Header and an IHDR chunk, every valid PNG file has an IEND chunk. So our main now includes the following lines:
int main(int argc, char *argv[]) {
[...snip...]
// Start reading Chunks to the End of File
CHUNK *chunk;
Chunks chunks = {0}; // little trick to store our chunks
while (true) {
chunk = read_chunk(inptr);
if (chunk == NULL) {
printf("Error reading Chunk or reached unexpected end of file.\n");
break;
}
printf("Chunk Type: %.4s\n", chunk->chunk_type.type_code);
[...snip...]
}
}
As shown above, I use a printf statement, for now, to show the chunk type. We need to keep reading chunks until we find the IEND chunk:
int main(int argc, char *argv[]) {
[...snip...]
while(true) {
[...snip...]
// Check if we reached the end of the PNG file
// (Last chunk is always IEND)
if (strncmp(chunk->chunk_type.type_code, "IEND", 4) == 0) {
printf("Reached end of PNG file.\n");
free(chunk->data);
free(chunk);
break; // this breaks the loop and triggers the program's exit
}
[...snip...]
}
// Here, we free some memory (not shown here yet),
// close the file, and exit
fclose(inptr);
return 0;
}
What if we just want to get some information, for now? That’s why we need the IHDR chunk! I use the following function to just pretty print these bytes in a way that makes sense.
Again, taken from PNG Specification. An IHDR Chunk contains:
Width 4 bytes
Height 4 bytes
Bit depth 1 byte
Color type 1 byte
Compression method 1 byte
Filter method 1 byte
Interlace method 1 byte
Width and height give the image dimensions in pixels. They are PNG four-byte unsigned integers. Zero is an invalid value.
Bit depth is a single-byte integer giving the number of bits per sample or per palette index (not per pixel). Valid values are 1, 2, 4, 8, and 16, although not all values are allowed for all color types.
Color type is a single-byte integer.
Bit depth restrictions for each color type are imposed to simplify implementations and to prohibit combinations that do not compress well.
So the code would look like the following:
// defines an IHDR Chunk
typedef struct {
uint32_t width;
uint32_t height;
uint8_t bit_depth;
uint8_t colour_type;
uint8_t compression_method;
uint8_t filter_method;
uint8_t interlace_method;
} __attribute__((__packed__)) IHDR_CHUNK;
// Try to retrieve information from IHDR Chunk
// Previously named "interpret_IHDR"
void print_image_info(CHUNK *chunk) {
printf("Length field contained in Chunk: %d\n", chunk->length);
IHDR_CHUNK *ihdr = (IHDR_CHUNK *)chunk->data;
printf("Width: %u\n", ntohl(ihdr->width));
printf("Height: %u\n", ntohl(ihdr->height));
printf("Bit depth: %u\n", ihdr->bit_depth);
printf("Colour type: %u\n", ihdr->colour_type);
printf("Compression method: %u\n", ihdr->compression_method);
printf("Filter method: %u\n", ihdr->filter_method);
printf("Interlace method: %u\n", ihdr->interlace_method);
}
It receives an already validated chunk of type Chunk and reinterprets the bytes of the data field into an variable of type IHDR_CHUNK. Then, in our loop, we can call this function like the following:
int main(int argc, char *argv[]) {
[...snip...]
while(true) {
[...snip...]
// Get some information
if (strncmp(chunk->chunk_type.type_code, "IHDR", 4) == 0) {
printf("Found IHDR... Getting some info:\n");
print_image_info(chunk);
// Copying
/* printf("Found IHDR... Backing up...\n"); */
/* ihdr_bak = (IHDR_Info *)chunk->data; */
}
if (strncmp(chunk->chunk_type.type_code, "IDAT", 4) == 0) {
da_append(chunks, chunk);
} else {
free(chunk->data);
free(chunk);
}
[...snip...]
}
[...snip...]
}
The IDAT Chunk
In the last code block, I went ahead and also show the comparison to check if we found the IDAT Chunk. A valid PNG file can contain one or more IDAT Chunks, and they contain very important information. It is precisely the IDAT Chunk or chunks what we would need to decompress, interpret and modify in order to make modifications to a PNG image.
Notice how as shown some code blocks above, I’m using a dynamic array to store all of the Chunks, although, I’m now realizing this logic is kind of clunky, I’m not entirely sure that’s the point at which I would need to store a chunk. But whatever, we’ll leave it as it is, for now. The dynamic array trick is pretty neat, and a classic in C programming (I just leardned about it though):
// dynamic array to deal with chunks
typedef struct {
CHUNK **items;
size_t count;
size_t capacity;
} Chunks;
#define da_append(xs, x) \
do { \
if (xs.count >= xs.capacity) { \
if (xs.capacity == 0) \
xs.capacity = 256; \
else \
xs.capacity *= 2; \
xs.items = realloc(xs.items, xs.capacity * sizeof(*xs.items)); \
} \
xs.items[xs.count++] = x; \
} while (0)
Here I am making it work with the type CHUNK, but the neat part is that we can use this same trick to work with any type. Although it is missing a lot of functionality, this is pretty much a basic implementation of C++’s std::vector<T>
Summary so far
At this point, the program does a few things:
- Opens the file
- Checks for a valid Signature Header, confirming if we indeed are working with a valid PNG file
- Reads Chunks into memory until reaching the end of the file (by checking for the IEND Chunk)
- Prints important information of the image obtained by the IHDR Chunk
- Has no memory leaks
The idea moving forward was to start working with those IDAT chunks, in order to maybe apply a filter to images. Think maybe a sepia filter, and that was it.
But then I kinda got a little bored. And I almost abandoned the project. I stopped working on it for two or three days, until…
Rewriting in… you guessed it
So yeah, due to my annoying habit of language hopping, or just plain boredom, after a couple of days I decided to write the entire thing in Rust. Oh my, the meme!
Like I meantion near the beginning of the post; I bought a copy of The Rust Programming Language (I like physical copies), Rust’s official book some months ago and took a go at it. Oh my, was it hard. Learning Rust (at least for me or my skill level) forced me to unlearn some habits or unlearn some stuff that I thought I understood, as well as made me hit the wall against stuff I never heard from before. The first try at learning Rust was kind of hard. At some point the frustration was too annoying, mixed with the idea that it would be too hard to find a job with Rust, and then I just, wait for it… HOPPED into another language. But then I kept coming back for short periods, kept reading around and discussing about programming in general in many places on the Internet. I haven’t realized but after some months, I was understanding more and more, funny how that works, learning. So yeah, this new attempt at Rust has been fruitful, so to speak. I feel quite confident, or at least way more confident than past times trying to write Rust.
So let’s see how this new version of the program looks like.
The code, same but different
For the sake of shortness, because this post is very long as it is, I will ommit some code snippets, like for example, checking the command-line arguments, opening the file and all that, I will also ommit explaining in detail the particularities about PNG files, the Signature Header, and the types of Chunks, and so son.
Checking if we have a valid PNG file
This looks similar to the C version, with a few security improvements:
const SIGNATURE_HEADER: [u8; 8] = [137, 80, 78, 71, 13, 10, 26, 10];
pub struct SignatureHeader {
values: [u8; 8],
}
impl SignatureHeader {
// Creates a Signature Header
// If an error occurs, we can say that we have an invalid PNG File
pub fn new(file: &mut File) -> Result<Self, Box<dyn std::error::Error>> {
let mut filebuff = [0u8; 8];
// read into buffer
match file.read_exact(&mut filebuff) {
Err(err) => return Err(format!("Error reading Signature Header: {err}").into()),
_ => (),
};
// Compare values
if filebuff.to_vec().iter().eq(&SIGNATURE_HEADER.to_vec()) {
Ok(SignatureHeader { values: filebuff })
} else {
Err("Mismatch in Signature Header".into())
}
}
}
In this code snippet, we can see some of Rust’s niceties in action. In a separate file, called png.rs, we are declaring a SignatureHeader struct into which we store the values as a slice of u8’s. In Rust, the impl block allows us to (among other details like implementing traits), declare methods for our structs. So as you can see, we are declaring a new method for our SignatureHeader struct. In here, we are pretty much doing what you’d expect by this point. reading, in a more safe manner, by using read_exact from our FILE into a buffer and then comparing the elements with the correct SIGNATURE_HEADER, and if everything goes well, we return our new SignatureHeader, indicating success. In this same line of thought, we can observe how Rust manages success states and errors by using Result<T, E>. Although fully explaining this goes way out of scope for this post.
This would be called like the following inside our main.rs :
// Read Signature Header and ensure if valid file
let signature_header: SignatureHeader = match SignatureHeader::new(&mut fileptr) {
Err(err) => {
eprintln!("{err} Invalid PNG File.");
process::exit(1);
}
Ok(signature) => {
println!("Valid PNG File.");
signature
}
};
Reading the Chunks
Again, in a file called chunk.rs we use a Chunk structure for orderly storage and access. We also define a new method to read our chunks. This helps our code to be more compact, ordered, and readable (kinda, because Rust is not particularly popular for being readable), than in our C version:
#[derive(Clone)]
pub struct Chunk {
length: u32,
chunk_type: [u8; 4],
data: Vec<u8>,
crc: [u8; 4],
}
impl Chunk {
// Constructor for new chunk
pub fn new(file: &mut File) -> Result<Self, Box<dyn std::error::Error>> {
let mut length_bytes = [0u8; 4];
match file.read_exact(&mut length_bytes) {
Err(err) => return Err(format!("Error reading Chunk's Length: {}", err).into()),
_ => (),
}
// Convert length to u32
let length: u32 = u32::from_be_bytes(length_bytes);
// Read Chunk Type
let mut chunk_type = [0u8; 4];
match file.read_exact(&mut chunk_type) {
Err(err) => return Err(format!("Error reading Chunk Type: {}", err).into()),
_ => (),
}
// Read data, using the length we obtained before
let mut data: Vec<u8> = vec![0; length as usize];
match file.read_exact(&mut data) {
Err(err) => return Err(format!("Error reading Data: {}", err).into()),
_ => (),
}
// Read CRC
let mut crc = [0u8; 4];
match file.read_exact(&mut crc) {
Err(err) => return Err(format!("Error reading CRC: {}", err).into()),
_ => (),
}
let chunk = Chunk {
length,
chunk_type,
data,
crc,
};
Ok(chunk)
}
}
Note: Yes, I know the managing of the errors is not ideal. But this is just pretty much a prototype so to speak.
Notice how in theory the logic for reading the fields of a Chunk from a file is the same, although with some quality of life improvements like read_exact and the built in u32::from_be_bytes, among other stuff. Way easier than carefully dealing with malloc.
The loop, storing the Chunks, and the IHDR Chunk
In main.rs, we use this method to read Chunks in our loop like:
// Reading chunks until we find IEND
// Be sure to print info from IHDR
let mut chunks: Vec<Chunk> = Vec::new();
loop {
// Huh, I'm not sure about this:
let curr_chunk: Chunk = match Chunk::new(&mut fileptr) {
Err(err) => {
eprintln!("Error reading Chunk: {}", err);
process::exit(1);
}
Ok(chunk) => {
// Pushing the chunk into the chunks Vec by cloning
chunks.push(chunk.clone());
chunk
}
};
// print some info from IHDR
// Just realizing maybe I need to think of a different approach when using the chunks
if curr_chunk.chunk_type_as_str() == "IHDR" {
println!("IHDR Chunk found!");
let ihdr: IhdrChunk = IhdrChunk::new(&curr_chunk);
println!("{:?}", ihdr);
}
println!("Chunk Type: {}", curr_chunk.chunk_type_as_str());
if curr_chunk.chunk_type_as_str() == "IEND" {
println!("IEND Reached!");
break;
}
}
For brevity, I included the entire loop in here at once. Notice how at the top, before the loop, we are using a Vec<T>, Rust’s built in implementation for vectors, in this case we are using a Vec<Chunk>, that is, a vector holding a collection of elements of type Chunk.
Also notice how we declare a curr_chunk (current) and assign to it the value of calling the Chunk::new method. This highlights one of the most acclaimed parts of Rust: Because a method like Chunk::new returns a Result<T, E>, where T is a generic type and E is a generic Error type, we can check if the return of this method is an error, or an actual correct value of type T, and act accordingly. As you can see, we use a match statement and if we encounter some kind of error, meaning a Chunk was not read for whatever reason, we inform the user and gracefully exit the program. How elegant! On the other hand, if a chunk was successfully read (denoted by the Ok(chunk)), we can store its value in curr_chunk.
Then, we store the correctly read Chunk into our Vec<Chunk>, as mentioned before, for later use.
Just like we did in the C version, we obtain the relevant information from interpreting the IHDR Chunk by using the IhdrChunk::new method. Here’s the code if you really want to see it:
#[derive(Debug)]
pub struct IhdrChunk {
width: u32,
height: u32,
bit_depth: u8,
colour_type: u8,
compression_method: u8,
filter_method: u8,
interlace_method: u8,
}
impl IhdrChunk {
pub fn new(chunk: &Chunk) -> Self {
let width: u32 = u32::from_be_bytes(chunk.data()[0..4].try_into().unwrap());
let height: u32 = u32::from_be_bytes(chunk.data()[4..8].try_into().unwrap());
let bit_depth: u8 = chunk.data()[8];
let colour_type: u8 = chunk.data()[9];
let compression_method: u8 = chunk.data()[10];
let filter_method: u8 = chunk.data()[11];
let interlace_method: u8 = chunk.data()[12];
IhdrChunk {
width,
height,
bit_depth,
colour_type,
compression_method,
filter_method,
interlace_method,
}
}
}
Back to the main loop, notice how we compare the Chunk Type of every Chunk to see if we have found the IEND Chunk, to break out from the loop.
Writing to output
Wait what? Yeah, at this point, this project is still kinda small and baby tier-ish. For now, and expanding above and beyond on the C project, I decided to try to at least write the same input file into a copy. This would mean I’m in the correct track manipulating these Chunks.
So, after we read all the Chunks and store them for later use, we can write their bytes to another file! First, we would need to create a new file
// new_filename was declared and initialized near the top of the program, it is just a String
let mut out_fileptr = match fs::File::create(&new_filename) {
Err(err) => {
eprintln!("Error opening output file: {err}.");
process::exit(1);
}
Ok(file) => file,
};
Notice how fs::<:create()> creates the file and opens it with the proper permissions, else it returns an error, and again, we handle both cases using match.
Then, we start to write all the data into this output file. Starting with the Signature Header and then all of the Chunks, one by one. For this, we need another method on our Chunk type to write the contents to a file:
#[derive(Clone)]
pub struct Chunk {
length: u32,
chunk_type: [u8; 4],
data: Vec<u8>,
crc: [u8; 4],
}
impl {
[...snip...]
// Writes contents of chunk to a file, in order
pub fn write_to_file(&self, file: &mut File) -> Result<usize, Box<dyn std::error::Error>> {
let mut total_written = 0;
// Write the length (as big-endian)
let length_bytes = self.length.to_be_bytes();
total_written += file.write(&length_bytes)?;
// Write the chunk type
total_written += file.write(&self.chunk_type())?;
// Write the data
total_written += file.write(&self.data())?;
// Write the CRC
total_written += file.write(&self.crc)?;
Ok(total_written)
}
[...snip...]
}
I am particularly proud of this method, despite the not so explicit error handling.
So we stated above, before the last code block, we start writing, this is how it looks like back in our main.rs :
// write signature header
match out_fileptr.write(&signature_header.values()) {
Err(err) => {
eprintln!("Error writing to file {}: {}", &new_filename, err);
process::exit(1);
}
Ok(size) => println!("{} bytes correctly written to {}", size, &new_filename),
}
// write chunks one by one
for chunk in chunks {
match chunk.write_to_file(&mut out_fileptr) {
Err(err) => {
eprintln!("Error writing data to {}: {}.", &new_filename, err);
process::exit(1);
}
Ok(size) => println!("Written {} bytes to {}.", size, &new_filename),
}
}
I would say that the readability of Rust is more or less on par with those of C or C++. And it deffinitively takes a little while getting used to. But still, notice how the structure of this code block, and the program in general, seems at least cleaner and better organized than our C version.
Summary so far
At this point, the Rust version of this program does the following:
- Opens the file
- Checks for a valid Signature Header, confirming if we indeed are working with a valid PNG file
- Reads Chunks into memory until reaching the end of the file (by checking for the IEND Chunk)
- Prints important information of the image obtained by the IHDR Chunk
- Stores each chunk safely
- Creates a new file and writes the Signature Header and each of the Chunks into this new output file
- Correctly writes into and closes this file.
The resulting file can be compared with tools like
- ls -l original.png output.png
- md5sum original.png output.png
Among others
Conclussion
What started as slowly and fearfully typing sentences in C, and nervously dealing with raw memory, evolved into an exciting and very fulfilling learning experience.
I feel like I could drop this little project at its current state. However I can admit that it currently is incomplete and I can still look into continue working into dealing with those IDAT Chunks and see if I can apply filters like, at least, Sepia, to images.
Regardless if I drop the project or keep pushing forward, I feel like a completely different programmer now. Dealing with stuff I always thought was beyond my comprehension as a (mostly) backend developer. Not to mention I refreshed my C skills by a long shot and I really learned a lot about Rust, an exciting and modern programming language. If this was my introduction to Systems Programming, I think it was satisfactory, and I feel excited to keep learning.
If you got to this point. Thanks a lot for reading. To be completely honest, this project is not THAT much of a big deal. It might be just a normal monday for you. But to me, it was a huge milestone. Again, thank you! And see you soon!
Stay Medieval ❤️🔥
>> Home